[Computer Vision] Anchor Boxes(앵커 박스) - 1
Object detection(객체 감지) 알고리즘은 일반적으로 많은 수의 영역 샘플링하고, 이 영역에 관심 개체가 포함되어 있는지 여부를 확인하고, 대상의 실측 Bounding Boxes(경계 상자)를 정확하게 예측하기
jungnamgyu.tistory.com
Anchor box와 bounding box가 비슷하게 느껴질 수 있습니다.
Anchor box는 bounding box의 후보로써, 수많은 box들을 통 틀어 일컫는 말입니다.
Bounding Box의 offset은 Bounding Box의 상대적 위치와 크기를 의미한다.(x, y, w, h)
Anchor Box 훈련 세트 Labeling 하기
훈련 세트에서는 각 Anchor box를 훈련 sample로 사용합니다.
객체 감지 모델을 학습하기 위해서는 Truth bounding box에 대해 두 가지 유형의 Label를 표시해야합니다.
- Anchor box에 포함된 대상의 category
- Anchor box의 offset
객체 감지에서는 먼저 여러 개의 Anchor box를 생성하고, 각 Anchor box의 category와 offset을 예측합니다.
def offset_inverse(anchors, offset_preds):
c_anc = d2l.box_corner_to_center(anchors) # (xmin, xmax, ymin, ymax)의 중심
c_pred_bb_xy = (offset_preds[:, :2] * c_anc[:, 2:] / 10) + c_anc[:, :2] # 예측한 (x,y)
c_pred_bb_wh = torch.exp(offset_preds[:, 2:] / 5) * c_anc[:, 2:] # 예측한 (w,h)
c_pred_bb = torch.cat((c_pred_bb_xy, c_pred_bb_wh), axis=1) # 예측한 offset(x, y, w, h)저장
# 예측한 offset을 기반 (xmin, xmax, ymin, ymax) 중심 반환
predicted_bb = d2l.box_center_to_corner(c_pred_bb)
return predicted_bb
예측한 offset에 따라 Anchor box의 위치를 조절하고 Anchor box를 통해 예측에 사용될 bounding box를 얻은 다음
최종적으로 예측에 사용될 수 많은 Anchor box를 필터링해서 가장 유사한 Bounding box를 출력하게 됩니다.
그렇다면 많은 Anchor box 중에서 Truth bounding box와 유사한 Anchor box를 어떻게 찾는 것일까요??
바로, 앞에서 말한 IoU를 이용해 찾게 됩니다.
그림을 예시)

Truth bounding box를 B, Anchor box를 A라고 가정합니다.
Truth bounding box의 크기는 n(B)로 Anchor box의 크기 n(A)보다 작습니다.
Truth bounding box의 인덱스$B_{j}$와 Anchor box의 인덱스$A_{i}$를 이용해 행렬 X로 표현 합니다.
$X_{ij}$는 $B_{j}$에 대한 $A_{i}$의 IoU입니다.
(left) 먼저 행렬 X에서 가장 큰 $X_{23}$을 찾고 i=2, j=3을 기록하고 i행과 j열의 모든 값을 지워버립니다.
(middle) left가 진행된 후, 가장 큰 $X_{71}$을 찾고, i=7, i=1을 기록하고 i행과 j열의 모든 값을 지워버립니다.
(right) middle가 진행된 후, 가장 큰 $X_{54}$을 찾고, i=5, i=4을 기록하고 i행과 j열의 모든 값을 지워버립니다.
그렇게 행렬 X의 모든 값들이 사라질 때까지 반복이 된다면 총 n(B)번 값이 저장 됬을 것입니다. n(B) < n(A)
또한 IoU의 Threshhold 값을 이용해 일정 값 이상만 할당할지 여부를 결정할 수도 있습니다.
예를 들어 $A_{2}$인 Anchor box가 왔을 경우 $A_{2}$에 할당된 $B_{3}$를 찾고, Positive Anchor Box로 분류하며,
$A_{3}$인 Anchor box가 왔을 경우 관련된 B가 없을땐 category만 Negative Anchor Box로 분류합니다.
Anchor Box를 이용해 분류를 할 때 수많은 Anchor Box가 생기기 때문에 유사한 예측의 Box들이 많아지게됩니다.
결과를 단순화하기 위해서 유사한 예측 Box들을 단순화할 필요성이 있는데, 이 때 사용되는 방법이 NMS입니다.
anchors = torch.tensor([[0.1, 0.08, 0.52, 0.92], [0.08, 0.2, 0.56, 0.95],
[0.15, 0.3, 0.62, 0.91], [0.55, 0.2, 0.9, 0.88]])
offset_preds = torch.tensor([0] * d2l.size(anchors))
cls_probs = torch.tensor([[0] * 4, # Predicted probability for background
[0.9, 0.8, 0.7, 0.1], # Predicted probability for dog
[0.1, 0.2, 0.3, 0.9]]) # Predicted probability for cat
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, anchors * bbox_scale,
['dog=0.9', 'dog=0.8', 'dog=0.7', 'cat=0.9'])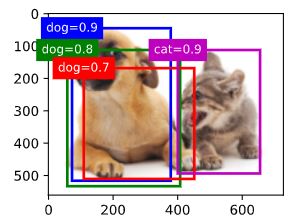
NMS(Non-Max suppresion) 비-최대 억제로 최대가 아닌 IoU를 억제한다는 것입니다.
각 Anchor Box에 객체탐지의 확률이 존재하고 가장 높은 확률의 앵커박스를 선택한 뒤
유사 Box들과의 IoU를 비교해 큰 Box(유사한 예측의 Box)를 억제해나가는 방식입니다.
def nms(boxes, scores, iou_threshold):
# sorting scores by the descending order and return their indices
B = torch.argsort(scores, dim=-1, descending=True)
keep = [] # boxes indices that will be kept
while B.numel() > 0:
i = B[0]
keep.append(i)
if B.numel() == 1: break
iou = box_iou(boxes[i, :].reshape(-1, 4),
boxes[B[1:], :].reshape(-1, 4)).reshape(-1)
inds = torch.nonzero(iou <= iou_threshold).reshape(-1)
B = B[inds + 1]
return torch.tensor(keep, device=boxes.device)
def multibox_detection(cls_probs, offset_preds, anchors, nms_threshold=0.5,
pos_threshold=0.00999999978):
device, batch_size = cls_probs.device, cls_probs.shape[0]
anchors = anchors.squeeze(0)
num_classes, num_anchors = cls_probs.shape[1], cls_probs.shape[2]
out = []
for i in range(batch_size):
cls_prob, offset_pred = cls_probs[i], offset_preds[i].reshape(-1, 4)
conf, class_id = torch.max(cls_prob[1:], 0)
predicted_bb = offset_inverse(anchors, offset_pred)
keep = nms(predicted_bb, conf, 0.5)
# Find all non_keep indices and set the class_id to background
all_idx = torch.arange(num_anchors, dtype=torch.long, device=device)
combined = torch.cat((keep, all_idx))
uniques, counts = combined.unique(return_counts=True)
non_keep = uniques[counts == 1]
all_id_sorted = torch.cat((keep, non_keep))
class_id[non_keep] = -1
class_id = class_id[all_id_sorted]
conf, predicted_bb = conf[all_id_sorted], predicted_bb[all_id_sorted]
# threshold to be a positive prediction
below_min_idx = (conf < pos_threshold)
class_id[below_min_idx] = -1
conf[below_min_idx] = 1 - conf[below_min_idx]
pred_info = torch.cat((class_id.unsqueeze(1),
conf.unsqueeze(1),
predicted_bb), dim=1)
out.append(pred_info)
return torch.stack(out)output = multibox_detection(cls_probs.unsqueeze(dim=0),
offset_preds.unsqueeze(dim=0),
anchors.unsqueeze(dim=0),
nms_threshold=0.5)
fig = d2l.plt.imshow(img)
for i in d2l.numpy(output[0]):
if i[0] == -1:
continue
label = ('dog=', 'cat=')[int(i[0])] + str(i[1])
show_bboxes(fig.axes, [torch.tensor(i[2:]) * bbox_scale], label)
가장 높은 확률의 (dog=0.9) Anchor Box를 선택했을 때 다른 Anchor Box를 비교해 보고,
IoU가 높은 (dog=0.8)과 (dog=0.7)을 억제합니다.
ref. Dive into Deep Learning, Aston Zhang and Zachary C. Lipton and Mu Li and Alexander J. Smola, 2020
'인공지능 > DeepLearning' 카테고리의 다른 글
| [Computer Vision] Single Shot Multi box Detection (SSD) (0) | 2021.01.20 |
|---|---|
| [Computer Vision] Multi scale Object Detection (0) | 2021.01.20 |
| [Computer Vision] Anchor Boxes(앵커 박스) - 1 (0) | 2021.01.19 |
| [Computer Vision] Object Detection and Bounding Boxes (0) | 2021.01.14 |
| [Computer Vision] Fine-Tuning (0) | 2021.01.12 |



