Anchor Boxes는 입력 이미지의 각 픽셀 중앙을 기준으로 여러 개의 Anchor Box를 생성했습니다.
이러한 Anchor Boxes는 입력 이미지의 여러 영역을 샘플링하는 데 사용됩니다.
하지만 Anchor Boxes가 이미지의 각 픽셀 중앙마다 생성되면 너무도 많은 Anchor Boxes가 생성되게 됩니다.
ex)
입력 이미지의 높이가 561, 너비가 728이라고 가정합니다.
각 픽셀마다 5개의 서로 다른 모양의 Anchor Boxes가 생성된다면
2백만개가 넘는 Anchor Boxes를 예측해야하고 이미지에 해당하는 Label을 지정해야합니다.
Anchor Boxes의 수를 줄이는 방법
- 입력 이미지에서 픽셀을 균일한 샘플링하여 샘플링 된 픽셀을 기준으로만 앵커박스를 생성
- 다양한 숫자와 크기의 Anchor Boxes를 여러 scale로 생성 ex) 1x1 모양의 객체는 2x2 모양의 이미지에서도 탐지가 가능합니다. 따라서 더 작은 Anchor Boxes를 사용하여 더 작은 개체를 탐지할 때는 더 많은 영역을 표본으로 추출하며, 더 큰 Anchor Boxes를 사용하여 더 큰 개체를 탐지할 때는 더 적은 수의 영역을 표본으로 추출할 수 있습니다.
Multi scale의 Anchor Boxes 생성
%matplotlib inline
from d2l import torch as d2l
import torch
img = d2l.plt.imread('../img/catdog.jpg')
h, w = img.shape[0:2]
h, w
CNN에서 2차원 배열의 출력을 feature map이라고 합니다.
feature map의 모양을 정의하여 모든 이미지에서 균일하게 샘플링 된 Anchor Boxes의 중간 점을 결정할 수 있습니다.
def display_anchors(fmap_w, fmap_h, s):
d2l.set_figsize()
# 처음 두 차원의 값은 출력에 영향을 주지 않습니다.
fmap = torch.zeros((1, 10, fmap_h, fmap_w))
# fmap의 크기만큼 x, y의 축을 나눠 fmap에서 상대적 위치를 저장합니다.
anchors = d2l.multibox_prior(fmap, sizes=s, ratios=[1, 2, 0.5])
bbox_scale = torch.tensor((w, h, w, h))
d2l.show_bboxes(d2l.plt.imshow(img).axes,
anchors[0] * bbox_scale)
display_anchors의 기능은 feature map의 각 픽셀 단위 중심에 Anchor Boxes를 생성하는 것입니다.
display_anchors(fmap_w=4, fmap_h=4, s=[0.15])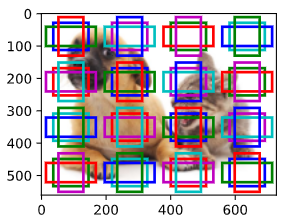
display_anchors(fmap_w=2, fmap_h=2, s=[0.4])
display_anchors(fmap_w=1, fmap_h=1, s=[0.8])
위와 같은 방식으로 multi scale에서 다양한 크기의 Anchor Boxes를 생성할 수 있습니다.
생성된 Anchor Boxes를 통해 다양한 scale에서 다양한 size의 객체를 감지 할 수 있습니다.
CNN을 통해 Multi scale을 구현하는 방법이 있습니다.
특정 scale에서 HxW의 모양을 가진 feature map으로 서로 다른 중간점을 가진 Anchor Boxes의 HxW set를 생성합니다.

$C_{i}$ feature map이 입력 이미지를 기반으로 한 CNN의 중간 출력이라고 가정합니다.
$C_{i}$ feature map은 서로 다른 공간 위치를 가지며, feature map의 ci 단위는 입력 이미지와 동일한 field를 가집니다.
따라서 ci 단위를 중간점으로 사용하여 Anchor Boxes의 category와 offset으로 변환할 수 있습니다.
ref. Dive into Deep Learning, Aston Zhang and Zachary C. Lipton and Mu Li and Alexander J. Smola, 2020
'인공지능 > DeepLearning' 카테고리의 다른 글
| [Computer Vision] IoU ; Intersection over Union (2) | 2021.01.20 |
|---|---|
| [Computer Vision] Single Shot Multi box Detection (SSD) (0) | 2021.01.20 |
| [Computer Vision] Anchor Boxes(앵커 박스) - 2 (0) | 2021.01.19 |
| [Computer Vision] Anchor Boxes(앵커 박스) - 1 (0) | 2021.01.19 |
| [Computer Vision] Object Detection and Bounding Boxes (0) | 2021.01.14 |



